목차
구글스프레드시트를 사용하며 데이터가 쌓이다보면 중복되는 경우가 생기기도 한다. 이걸 일일이 대조하여 제거하거나 수정하는 일은 여간 번거로운게 아니다.
Office365에는 업데이트를 통해 unique함수가 생겨났는데, 이전 버젼을 이용하는 사람이라면, 고급 필터 등 번거로운 기능을 거쳐야만 한다. 이럴 때 구글스프레드시트의 unique 함수는 적절한 대안이 된다.
Unique 함수 사용하기
unique()는 말 그대로 특정 범위내 여러 값들의 중복을 제거해 준다.
기본 사용
기본 사용법은 간단하다.
unique 안에 범위를 지정하면 된다.
=unique(범위)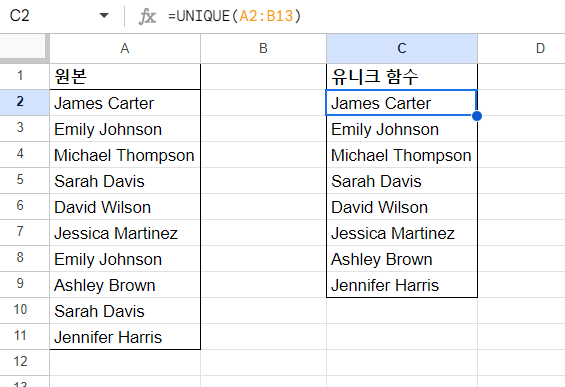
유니크 함수 기본 사용 결과
원본 데이터에서 2회 사용된, Emily Johnson과 Sarah Davis는 유니크 함수 결과에서는 1회만 나왔다.
항목이 여러 개인 경우
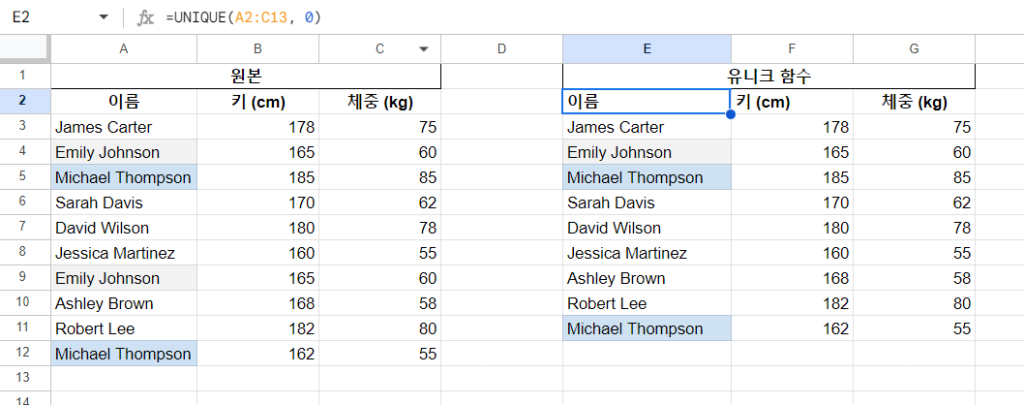
기본적으로 Unique는 여러 열을 동시에 비교한다. 두 번 중복하여 기록되었던 Emily Johnson은 유니크 함수 결과에서 한 명으로 줄어들었다. 반면, Michael Thompson은 원본에서는 2명처럼 보였으나, Unique 함수로 필터링 하고 보니 키도 체중도 다른 동명이인으로 확인되었다.
Unique 함수 응용하기
응용1. unique() + countif()
Unique 함수는 중복을 걸러줄 뿐, 몇 번 등장했는지는 확인 시켜주지 않기 때문에 횟수가 중요하다면 위의 조합을 사용할 수 있다. Countif()는 조건에 맞는 값의 횟수를 세어주기 때문에 우리는 이 둘의 조합으로 각 값이 몇 번 등장했는지 알 수 있다.
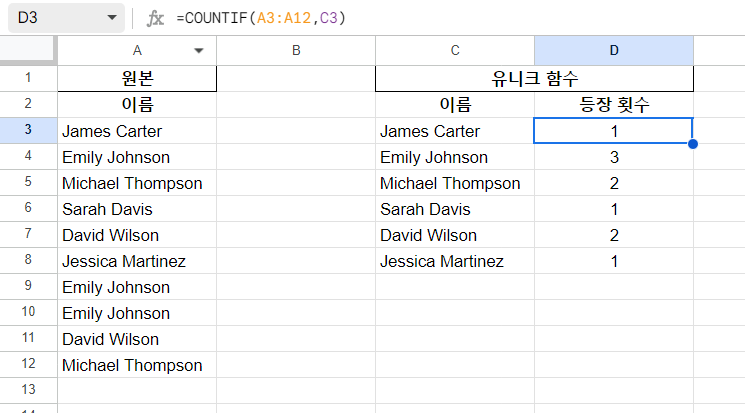
참고로, 위 예시에서 쓰인 countif 함수의 사용 방법은 아래와 같이 쓰였다.
=countif(범위, 조건)좀 더 자세한 사용 방법은 아래 글을 참조.
구글스프레드시트, 조건에 맞는 셀의 숫자 세기(countif 함수 사용 방법 및 응용)
응용2. unique() + flatten()
필터링 대상이 항상 한줄로 있으란 법은 없다. 각자의 작성 스타일, 혹은 사용 중인 양식에 따라 Unique로 중복을 제거해야하는 값들이 멀리 떨어져 있거나, 여러 개의 열로 나뉘어 있을 수 있다.
앞선 예제에서도 보았듯이, unique를 다수열로 범위 지정하는 경우, 행을 묶어서 판단하기 때문에 각 행이 묶음이 아닌 경우에는 적용이 곤란할 수 있다.
그럴 땐, flatten의 사용으로 간단히 해결이 가능하다.
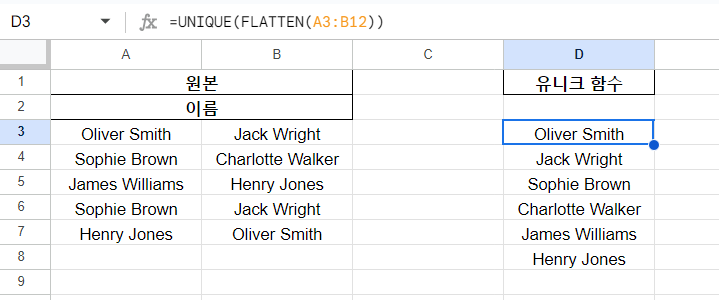
참고로, flatten 한 개, 혹은 여러 개의 범위를 하나의 열로 만들어 준다.
=flatten(범위1, 범위2...)작성한 수식은 다음과 같다.
=UNIQUE(FLATTEN(A3:B12))위 수식을 통해 A3~B12의 범위를 한 열로 만든 후 unique 함수가 적용되어, 중복 값이 제거된 결과를 얻을 수 있다.
구글 문서에서도 Unique 함수 관련 예시를 확인 할 수 있다.
“구글스프레드시트, 중복 값 제거하기 (Unique 함수 사용 및 응용)”에 대한 2개의 생각